Abstract:时间线来到了2018,此时此刻关于亚马逊的运营已经到了一个瓶颈期,一方面大量的卖家涌入,导致竞争已经非常激烈,另外一方面平台对于操纵review的打击力度已经非常大,基本都是一撸到底的节奏。PPC广告已经非常的贵,没有数据化选品的支撑,单靠运营,一般的产品利润已经非常低,而风险又非常大,这就导致了选品的难度指数级的上升,要做到选品的准确性,数据挖掘,文本挖掘技术就是电子商务的必然的趋势,获取数据总是从创造一个高效的爬虫开始的。很少能看到相关的技术文章,我就整理写一些我的看法吧,转载请注明出处。
一,为什么要自己开发爬虫
现在市面上的选品工具-以Junglescout为代表都是用爬虫封装的。一方面确实是方便了选品,几年前用它可以很方便的开发产品,但是别忘了现在已经是2018,Junglescout 已经被很多卖家使用,如果跟别人用同样的方法获得的结果只能是大概相似,自己做的定制化爬虫是第一手数据,数据的专业度,新鲜度,可靠性都可以强过第三方工具。
二, 爬虫可以帮助亚马逊卖家得到什么
爬虫帮你获得如下数据:
(1)Avg Price平均价格
(2)Inventory库存数量
(3)Qty/Day 日销量
(4)Est.sales 月销量
(5)Revenue/Day 日营业额
(6)Rank 排名
(7)Sellers卖家数量
(8)Category 类目
(9)甚至亚马逊相关站外相关信息 爬虫可以获取更多数据……
三, 爬虫的作用
1、 如果你爬虫爬出相关行业top1000数据,那你的选品范围就增大了,然后按照你的资源资金和竞争情况等选取细分产品价格等进行开发。
2、通过爬虫数据,跟踪市场产品和竞争对手价格和库存评论等,用来做出快速反应。
3、利用爬虫信息,抓取亚马逊站外促销信息以及站内舆论信息等数据,抓取亚马逊类目变动情况。
4、事实上爬虫只是数据挖掘的第一步,用爬虫去获取数据,怎么去寻找数据的关联,通过Python的Pandas模块分析数据,可以统计出平均数,标准差等信息,matplotlib模块把数据可视化,数据挖掘是通过大量的数据,通过数据的预处理,挖掘建模(分类,聚类,关联,预测),可以从网站的用户行为数据中挖掘出用户的潜在需求, 发现事物之间的规律。
四, 亚马逊的反爬虫机制
1、服务器对爬虫程序会自动屏蔽。
2、登陆后才能访问,发现异常就封号 。
3、记录 IP,发现异常就封 IP 。
4、各种图灵测试,验证码是其中一种。
针对亚马逊的爬虫机制,能采取的应对措施。
1、把爬虫程序伪装成浏览器,通过报头进行。
2、防屏蔽手段还有通过代理服务器,通过程序自动经过代理IP池用不同的IP登录。
3、针对一些图灵测试,主要是通过抓包分析,找到在HTML隐藏的网址,通过Post.Request请求
亚马逊的爬虫程序最高效的还是用scrapy 框架去构建,scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
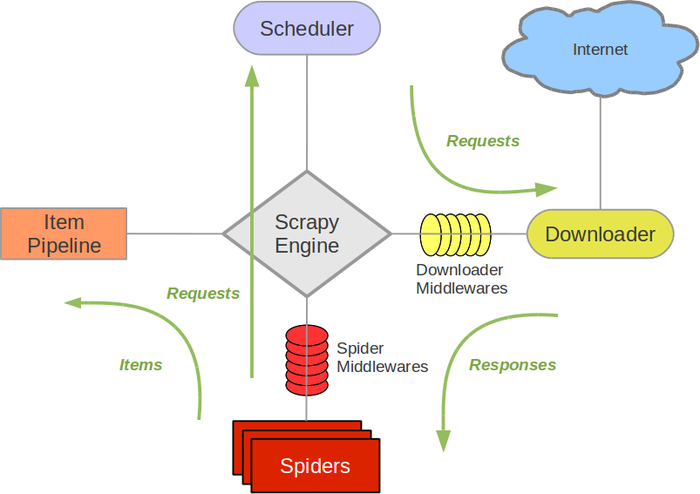
Scrapy 的底层是Python 的Urllib库,HTML源码的数据和网址的提取主要依靠正则表达式跟X-pass表达式。
以下是我做的一个简单爬虫
Sourcing Url: https://www.amazon.com/Best-Sellers/zgbs/
sales ranker spider:
import scrapy
from pydispatch import dispatcher
from scrapy import signals
from amazon.helper import Helper
from amazon.items import SalesRankingItem
from amazon.sql import RankingSql
class SalesRankingSpider(scrapy.Spider):
name = 'sales_ranking'
custom_settings = {
'LOG_LEVEL': 'ERROR',
'LOG_FILE': 'sales_ranking.json',
'LOG_ENABLED': True,
'LOG_STDOUT': True
}
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.items = []
dispatcher.connect(self.load_asin, signals.engine_started)
def start_requests(self):
for item in self.items:
yield scrapy.Request('https://www.amazon.com/dp/%s' %
item['asin'], self.parse, meta={'item': item})
def parse(self, response):
product_detail =
response.xpath('//div/table').re(r'#[0-9,]+(?:.*)in.*\(.*[Ss]ee
[Tt]op.*\)')
if len(product_detail) == 0:
product_detail = response.css('div
#SalesRank').re(r'#[0-9,]+(?:.*)in.*\(.*[Ss]ee [Tt]op.*\)')
if len(product_detail) != 0:
item = SalesRankingItem()
key_rank_str = product_detail[0]
key_rank_tuple = Helper.get_rank_classify(key_rank_str)
item['rank'] = Helper.get_num_split_comma(key_rank_tuple[0])
item['classify'] = key_rank_tuple[1]
item['asin'] = response.meta['item']['asin']
yield item
else:
raise Exception('catch asin[%s] sales ranking error' %
response.meta['item']['asin'])
def load_asin(self):
self.items = RankingSql.fetch_sales_ranking()
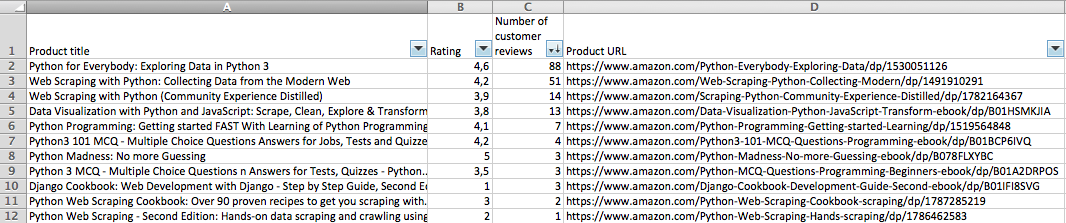
关键字“Pathon” 输出:
亚马逊的发展趋势
2018年跨境电商这个行业已经有了颓势迹象,以往靠整合资源野蛮增长的年代已经过去了,虽然这个行业还不断的有新人涌进来,事实上,很明显在这种环境中能继续发展的小卖将来无非是两种,一种是深挖产品类目,有足够产品行业知识,并且有一定工厂资源的卖家,另外一种就是重视IT,有足够数据挖掘能力的卖家。